


0x00 前言
我有很长一段时间没有更新与web安全有关的内容了,这两天我学习了一下Vue,今天我就将我所学到的一些内容汇总到这篇文章中并分享出来。
注:
1.本文不会涉及到fuzz js文件。
2.本文假设读者已经掌握了html、js。
3.本文会涉及到vue基础知识、判断目标站点是否是vue框架、vue引入js的方式、Vue Router、vue路由守卫、绕过vue路由守卫。
4.本文不会去讲vue基础语法。
5.本文不会去讲过多的vue router的内容,但是接下来我还会发一篇文章具体讲一下vue router。
6.本文将公布我写的绕过路由守卫的Hook脚本以及其思路,思路与市面上流行的绕过思路不一样,我个人认为能秒杀路由守卫,真正实现hook绕过。
7.本文主要针对的是用vue框架构建的单页应用(SPA),下文会阐述单页应用的定义。
8.如有读者时间匆忙,可以直接跳到最后的0x06总结,但我还是建议读一遍文章,我认为本文还是有很多内容值得学习的。
目录:
0x01 正文
0x02 前置知识
0x03 Vue Router
0x04 prefetch
0x05 路由守卫
0x06 总结感谢Maraschino师傅(公众号:Dig Manual)能在凌晨与我一起研究,在这段时间Maraschino师傅与我探讨过很多东西,让我能在这个浮躁的时代安心下来去学习,感激不尽。
0x01 正文
实际上,我们收集目标站点下所有js文件无非就是想通过正则匹配,获取这些js文件当中写死的api以及可能存在的一些敏感信息,而获取这些内容的前置条件就是获取js。在讲解如何获取js之前,我们需要先了解一些Vue的基础知识。
0x02 前置知识
vue实际上就是一个Web前端框架,中文文档:https://cn.vuejs.org/,我们可以利用这个框架快速搭建起一个用户界面。
下面我们就使用官方脚手架快速搭建起一个vue开发环境:
注:脚手架可以被视为是一个框架,这是一个建筑学概念。实际上脚手架是CLI(Command-Line Interface)命令行界面,我们可以通过官方发布的 vue.js 项目脚手架快速搭建 vue 开发环境,通过下面的图示各位就能明白脚手架是何物了。
输入命令:
npm create vue@latest
✔ Project name: … <your-project-name> ✔ Add TypeScript? … No / Yes ✔ Add JSX Support? … No / Yes ✔ Add Vue Router for Single Page Application development? … No / Yes ✔ Add Pinia for state management? … No / Yes ✔ Add Vitest for Unit testing? … No / Yes ✔ Add an End-to-End Testing Solution? … No / Cypress / Nightwatch / Playwright ✔ Add ESLint for code quality? … No / Yes ✔ Add Prettier for code formatting? … No / Yes ✔ Add Vue DevTools 7 extension for debugging? (experimental) … No / Yes Scaffolding project in ./<your-project-name>... Done.

然后依次执行:
cd vue-project
npm install
npm run dev
现在我们就成功搭建起了一个vue环境,访问http://localhost:5173/:

我先来讲一下该框架下的一些文件夹和文件都有什么用:
•node_modules:
该文件夹下的内容是我们刚刚创建的vue项目中所需的一些依赖。

我们刚刚执行的npm install所安装的依赖就存放在里面。
•public:
专门用于存放一些静态资源的文件夹。

•package.json
打包配置、启动脚本

devDependencies: 开发时所依赖的工具包;
dependencies:项目正常允许时需要的依赖包;

•src

存放项目源代码的核心位置。
我们可以从上图中注意到,在src目录下有一个.vue文件:

template标签内部的内容就是我刚刚访问的搭建好的vue站点渲染出来的内容:

而我们可以看到在根目录下只有一个index.html:

实际上浏览器正常来说是不会加载vue文件的,这也就是说这些vue文件被引入到了index.html中(至于如何引入的我会在后文中讲)。让我们来看看官方文档描述:


文档向我们说明了.vue文件可以被称之为单文件组件,这些组件封装了js、html、css,例如我们刚刚看到的App.vue:

这也就是我想讲的第一个知识点:如何辨别一个站点是否采用了vue框架,在文档的最下面有一句话:单文件组件是 Vue 的标志性功能,并且我们也知道浏览器正常来说不会加载vue文件,它只认html、css、js,所以这就是典型vue项目的一个特征:它们通常只会有一个index.html,也就是说在vue项目中这些vue组件都会被引入到index.html,我们就能只在这一个页面中形成各种交互,这就是所谓的单页应用SPA(Single Page Application):

这也是我认为比较危险的一个点,传统前端开发时都是会写很多html,我这里就拿后台管理举例。比如一个后台管理有以下这几个html、js:
login.html (后台登录的html)
login.js (后台登录页面所需的js)
index.html (后台首页的html)
index.js (后台首页所需的js)在login.html中可能不会引入index.js,因为不需要,这就导致我们需要自行fuzz后台所需的js文件名并下载下来查找后台的一些api。而在vue项目(特指SPA)中就不需要,整个vue项目所需的js实际上都会写入到代码中,比如我们进入了一个vue站点,它虽然可能不会引入后台需要的js,但是在代码中我们就能找到这些js文件名,这就是我认为它比较危险的一个点。
讲完了上面这些内容后,再来让我们看一下index.html内部都有什么内容:

可以看到在body中有一个id为app的div,紧接着引入了src目录下的main.js:

为了理解这段代码,我们还是先看一下文档描述:

每个Vue应用都是通过createApp这个函数去创建一个新的应用实例。

我们传入到createApp函数里的对象实际上是一个组件,例如main.js中引入的是App.vue:

而每个Vue应用都需要一个根组件,其他组件将作为子组件,所以我们传入的App.vue就会变为该vue应用的一个根组件。
另外vue项目实际上也可以不使用单文件组件,所以说vue其实不止可以构建单页应用(SPA),它也可以构建多页应用(MPA)、静态站点生成(SSG)、服务端渲染(SSR) 等各种类型的应用,SPA 只是其中最流行的一种模式,但不是唯一的选择,只是本文目标主要针对的是单页应用,后文还会讲为什么。如果使用的是这种单文件组件,我们就可以直接将一个vue组件导入进来作为根组件,就比如main.js做的动作。

从文档中我们可以知道,应用实例必须在调用了mount()方法后才会被渲染出来,也就是说App.vue中的内容需要挂载才能被渲染出来,而createApp函数会返回一个应用实例,此时我们就可以进行挂载应用,用这个实例去调用mount方法,不过这个方法还需要接受一个容器参数,里面可以是一个DOM元素或是一个CSS选择器,比如官方创建的项目中是一个div:


挂载之后应用根组件(App.vue)的内容就会被渲染在容器元素中,也就是我们访问站点时渲染出的内容,这就是main.js所做的事。
总结来说,main.js可以被视为是一个桥梁,它将我们所写的vue组件渲染在index.html中,所以一般称main.js为入口文件,它负责初始化 Vue 实例等动作。
所以根据以上的内容我们也可以知道,无论是在官方脚手架搭建的vue项目还是在官方文档中,默认给的容器是id为app的div,一般情况下开发为了省事可能不会去更改这个特征,所以我们可以判断页面中是否存在这个div从而快速的判断目标站点是否是vue框架;当然这个值也是可以改的,所以这样判断也有很多的缺陷。不知道各位是否还记得vue挂载应用时是需要接受一个容器参数的,这个参数可以是一个DOM元素或是一个CSS选择器,所以理论上站点中任意一个DOM元素都可以被充当为一个挂载应用的容器,所以我们可以去遍历这些DOM元素去判断目标站点是否是vue框架,我看了一下VueCrack插件,这个插件使用的hook脚本就实现了我上面所说的遍历:

function findVueRoot(root, maxDepth = 1000) {
const queue = [{ node: root, depth: 0 }];
while (queue.length) {
const { node, depth } = queue.shift();
if (depth > maxDepth) break;
if (node.__vue_app__ || node.__vue__ || node._vnode) {
return node;
}
if (node.nodeType === 1 && node.childNodes) {
for (let i = 0; i < node.childNodes.length; i++) {
queue.push({ node: node.childNodes[i], depth: depth + 1 });
}
}
}
return null;
}
可以看到这段代码成功的找到了我们挂载的容器,我问了下ai__vue_app__、__vue__、_vnode都是什么,因为在官方文档中貌似没有提到这三个属性是什么:


我们使用的是vue3,来看一下这个实例里面都有什么:

可以看到__vue_app__就是我们上面所说的vue的应用实例,比如mount方法就在这个实例当中。代码通过判断节点是否有__vue_app__属性来判断网站是否是vue框架,这就是一种有效判断目标站点是否是vue框架的方法。
0x03 Vue Router
平时大家应该会刷到一些文章,讲如何绕过路由守卫,事实上路由守卫是Vue Router的一个功能,Vue Router是Vue.js 的官方路由,文档地址:https://router.vuejs.org/zh/。所以如果我们要了解路由守卫就必须先了解Vue Router。
安装vue router:
npm install vue-router@4

可以看到依赖里多了vue-router,说明我们安装成功了。
现在我给大家看一下我自己写的一段路由实例:
import {createRouter, createWebHistory,createWebHashHistory} from 'vue-router'
// 这里定义一个数组是用来存储路由的,在这个数组内就能自定义路由
// 每个路由是一个对象
const routes = [
{
path: '/',
// 第一个属性是path,也就是用户访问的路径
// alias: "/home",
alias: ["/home","/test"],
component: () => import('../views/index.vue'),
},{
path: '/content',
// 第一个属性是path,也就是用户访问的路径
component: () => import('../views/content.vue'),
}
]
// 此时只创建了路由规则,还需要创建路由器
const router = createRouter({
//第一个属性history,它有两种模式,第一种createWebHistory也就是浏览器一般使用的属性。
// history: createWebHistory(),
//第二种模式是createWebHashHistory,使用的url的#符号之后的部分模拟url路径的变化,因为不会触发页面刷新,所以不需要服务端支持。
history: createWebHashHistory(),
//创建一个路由器肯定就需要一个路由规则,上面定义的数组就是路由规则
routes
})
//导出路由器
export default router
我们需要了解两个概念,一个是路由规则一般会放在一个数组里,我们可以在这个数组里自定义路由,也就是像我图示的那样定义:

另一个概念是我创建路由器时所定义的history属性,history有两种模式,第一种是createWebHistory,这种模式是站点普遍使用的模式,我先给大家看一下效果:


可以看到,访问/test后输出了相对应的页面内容,现在我们换成第二种模式createWebHashHistory:

访问站点:

可以看到路径后多了#,我们在切换路由的时候就直接在这个#号后写即可,例如/#/content:

那么这两种模式有什么区别,我这里拿官方文档的原话来向大家说明区别:

这就是后者所干的事,前者需要从服务器重新加载,而后者不会,这就是它们两者的区别。我们日常测试时也不可避免的会遇到这两种站点,如果路径表现为后者这种,那么也可以作为我们判断是否是vue框架的一个标准。
接下来我们再回过头来具体看一下路由规则中的每一个属性都是干什么的:

首先我们先来了解一下path、alias和component属性都是干什么的,每个路由规则里的path实际上就是我们可以访问的路由,例如在数组中我定义了/和/content两个路由,现在我访问一下/:

/content:

成功访问了这两个路由,那么我们也可以看到,在第一个对象中有一个alias属性,这个属性里有一个数组,里面存了两个路径,其实这个属性是用来定义别名的,我们来看一下官方文档:

也就是说alias里设置的路径将会被作为是path的别名,例如我在代码中写了两个别名路径/home和/test,访问之后实际上响应的还是/的内容:


最后一个component属性比较重要,这个属性代表我们访问的目标路径加载什么组件,比如/加载../views/index.vue组件,我来给大家看一下这个组件内部是什么:

这就是我上面访问/、/home和/test返回的内容,这也就是说我们访问/content路径后会返回../views/content.vue组件的内容:

访问:

可以看到和我们想得一样。
现在让我们来看一下在生产环境中的代码和我们上面这些开发环境中的代码有什么不同,因为在生产环境中我们看到的都是html、css、js,而在开发环境中我们看到的是vue组件,使用下面这条命令就可以将 Vue 项目打包为生产环境可用的静态文件:
npm run build
搭建站点并访问:

可以看到访问/后加载了index-CbXXKHXe.js和index-CbgB4vtk.js这两个js,现在让我们访问/content试一下:

可以看到多出来一个js,说明这就是我们引入的content.vue组件:

为了确定以上的猜测,我们现在在组件当中写一个console.log:

重新打包并访问站点:

访问/后并没有打印数据,这证明我们没有访问content就不会加载content所需的组件:

现在我们访问/content试一下:


这印证了我刚刚所说的,只有访问了目标路径才会加载所需的组件js,我们来全局搜索一下我刚刚写的两个路由:


可以看到在代码中明确写了我们访问/就会加载/index-CkiZteHc.js,访问/content就会加载/content-Cs353m70.js。
通过这种方式我们就能获取到目标站点各路径所要用到的js,但其实在实际案例中可能没有这么简单,例如:

这种引入js的方式和我们刚刚看到的不一样,它并没有给出完整的js文件名,我给大家断点跟一下:




最终引入了login组件要用到的js,这就是传统的Webpack打包,所以我们可以看到在vue中其实可以有不同的方式引入js,但其实不管哪种方式,我们都能在代码中找到每个组件要引入的完整js文件名,这是毋庸置疑的,但是这两种方式对我们收集js还是有缺陷的,第一种方式可能没什么阻碍,能直接看到引入的js文件名,但是我们还得手动去代码中找;第二种方式也需要去代码中找,而且还需要自行拼接,所以这两种方式对我们收集js都有一定的阻碍,那么我现在就要引入另一种获取这些js的方法,那就是直接访问这些路由(有可能会遇到路由守卫的阻碍,后文会讲如何绕过)。
当我们直接访问这些路由后,js就会自动引入这些路由所需的js,比如我上面访问/content后就自动引入了content路由所需的js,这是最便捷的方式。
所以此时我们就引出了第一个问题:该如何找到所有路由?
第一种方式就是全局搜索路由并自行拼接,一般路由规则都会写在一起的,所以找起来还是比较方便的,例如:

我们可以一个一个访问,这样就能直接加载这些路由所需的js了,不过我在上面并没有和大家讲路由规则中的一个children属性,我给大家看一下我写的案例:

可以看到,我通过children属性给/user路径添加了两个子路由info和order,我们只需要将这两个路由各自添加到/user后就能访问了,例如:


而我们也可以注意到在最开始有一个path为空字符串的路径,这其实是一个默认页,并且里面也引入了一个default组件,而/user实际上也引入了user组件,这会不会冲突呢?其实是不会的,当访问/user后会显示 user.vue + default.vue,当访问 /user/info 会显示 user.vue + info.vue,所以user.vue通常作为一个布局的容器,比如用户页面的公共结构(头部、侧边栏、导航等)。我费这么多口舌讲这些实际上是因为当目标站点设置了很多子路由的时候就需要我们手动拼接,这样会很费时间,例如下面这个案例:

我给大家断点看一下里面的内容:

可以看到数组里的内容实际上就是system的子路由,尝试拼接:
/system/info
/system/work
/system/skill
/system/award
/system/education
/system/project这就是system下的所有子路由,但是这种方式对于我们来说比较繁琐,我们还需要在代码中寻找并手动拼接,那么有没有更便捷的方式,答案是有的。我们可以使用findsomething来寻找这些路由:

但是大家也可以看到,findsomething只找到了父路由,而并没有找到子路由,这其实是因为子路由不用写/:

这是我刚刚给大家看到的system下的子路由,由于没有/导致findsomehing并不能匹配到这些路由,所以我们只能找到父路由,此时我们就可以换一个插件—-VueCrack,github地址:https://github.com/Ad1euDa1e/VueCrack:

通过这个插件我们就能匹配到目标vue站点下的所有路由,其实我原本也是想写一个脚本来进行获取的,但是我发现已经有人写好了就没必要再去重复造轮子了。
所以现在我们就能通过VueCrack提供的路由挨个访问,这样就能快速获取到目标站点下所有js,但是这样就十全十美了吗,答案是错的,这就引出了我们这篇文章的第三个板块—-路由守卫,但在讲路由守卫和如何绕过路由守卫之前,我还需要讲一个小技巧。
0x04 prefetch
不知道各位在平时测试vue站点时是否遇到过下面这种案例:

这是一个vue站点的首页,也就是我们俗称的index.html单页,上面我也讲过了vue可以是一个单页应用SPA,这里就不重复说了。那么在这个首页中它引入了这么多js,和我们平时遇到的那种不同,比如我在之前给大家看过一个案例,它是进入某个组件后才会加载所需的js,而这个案例它虽然也会这样,但是它在index.html中就引入了所有组件需要的js,那么这个案例为什么要这么做,以及这么做对我们收集js有什么影响,这是我接下来要解答的问题。
首先我们可以看到在标签中有一个rel属性,属性值为prefetch,MDN介绍:

也就是说浏览器会事先获取和缓存这些资源,我们看一下F12:

可以看到浏览器确实请求了这些资源,让我们看看响应:

可以看到虽然浏览器请求了,但是在响应中实际上不会显示出内容的,这就是prefetch属性的特点,它会缓存所有的js但是不会在开发者工具中显示出内容,而是只会在进入相对应的组件才加载所需的js,比如我进入一个路由给大家看一下它是如何引入的:


让我们再来看看首页是否预加载了这个js:

这就是此类网站的特点,进入首页后它会先预加载站点所需的所有js,并且不能在开发者工具中看到响应的内容,必须得进入相对应的路由才能加载它所需的js,并且我们也能在开发者工具中看到响应的内容,上面我毕竟给大家看过了,它append了一个script标签,这样引入js完全是能在开发者工具中看到它的响应内容:

这就是这一类网站与我们上面所说的一类网站的区别,那么为什么要这么做,下面是deepseek给我的答复:

主要还是考虑到用户体验,通过预加载可以显著提高用户体验,当用户切换路由时能直接加载所需的js。
后来经过我和Maraschino师傅的研究后,针对此类网站对我们有什么影响也有了全面的解答:
1.此类预加载js网站不会对findsomething(熊猫头)插件正则匹配造成实质性的影响,依旧能正常实现匹配这些预加载的js。2.如果我们不开开发者工具,在burp中是不会有这些js的流量的,这是因为浏览器走的是缓存,如果想在burp中看到加载这些js的流量,那么就需要打开F12中的网络,并打开停用缓存:

然后再刷新网站,js就能正常的走网络请求了,而不是走缓存。3.此类网站对我们造成的影响只有我给大家在上面展示的:无法在F12中看到响应的内容。
所以说我认为这种预加载js的站点对我们造成的影响只有好处没有坏处,毕竟我们能直接在首页中就能获取到每个路由所需的js,就不必访问每个路由去获取这些路由所需的js了,如果你实在是想在F12中就能搜到你想搜的内容,不如直接开着F12并打开停用缓存的设置访问网站,burp里就能直接看到,这就是解决方案。
另外可能有朋友会疑惑,为什么这些js预加载了但是在源代码中搜不到,其实就是因为这些js没被引入,如果引入了就能搜到,而我们上面看到的预加载js,并没有真正执行,和真正引入是有区别的。
最后我在这里也推荐大家在开发者工具打开停用缓存的设置,这样对我们在burp中匹配敏感信息是有帮助的。
0x05 路由守卫
我们终于要讲到路由守卫了,官方文档:https://router.vuejs.org/zh/guide/advanced/navigation-guards.html,官方将这个功能称呼为导航守卫,我们依旧在下文中将这个功能称之为路由守卫。我们来看一下在官方文档中对路由守卫的具体描述:

通过描述我们可以知道,在前端设置路由守卫可以实现跳转或取消的方式守卫导航,说白了就是可以控制是否跳转到某个路由,在一些后台系统中,由于路由守卫的存在,妨碍了我们访问各个路由获取其js,所以我们就需要绕过这个东西。
路由守卫分为很多种:

我们先来聊聊全局前置守卫,也是最常用的一个路由守卫:


我们可以从文档中知道,当在beforeEach方法中return了false,就取消了用户的导航,那么URL就会重置到from路由对应的地址,也就是当前导航正要离开的路由;另外还有一点我们需要注意,读者朋友们可以发现,在设置全局前置守卫时,里面传递的实际上是一个箭头函数:

这点需要我们记住:设置全局前置守卫实际上就是传递一个函数进行设置。下面是一个全局前置守卫的示例:

// 添加全局前置守卫
router.beforeEach((to, from) => {
// 检查是否要访问 /user 路径或其子路径
if (to.path.startsWith('/user')) {
// 禁止访问,取消导航
console.log('禁止访问用户路由:', to.path)
return false
}
// 对于其他路由,允许正常访问
return true
})可以看到我判断了用户要去往的路由是否是/user或其子路径,如果是就return false禁止访问,也就是取消导航,路由就会变回之前的导航,如果是其他路由就允许正常访问,现在我们将站点搭建起来访问一下看看是否生效:

访问/user看看是否能访问成功:

可以看到访问/user后直接退回到了/,说明路由守卫起作用了,尝试访问下user的子路由order看看是否能访问成功:

成功取消导航,说明我们设置的全局前置守卫没问题。
那么接下来我就要和大家讲一下如何绕过全局前置守卫(注:我这里只是讲一下如何绕过全局前置守卫,路由守卫有很多种模式,我现在讲的这种绕过只是针对全局前置守卫,其他的路由守卫模式该如何绕过我后文还会再讲)。首先我需要将源码打包并搭建起来,因为浏览器毕竟加载的都是html、js:

访问站点:

成功访问,现在我们全局搜一下/user定位一下路径:

可以看到上面就是我写的路由规则,下面就是我在源码中设置的路由守卫,我们打一个断点跟一下:


s就是我们刚刚写的全局前置守卫:

所以我们可以知道:vue配置全局前置守卫实际上就是将我们写的函数放到一个数组里:

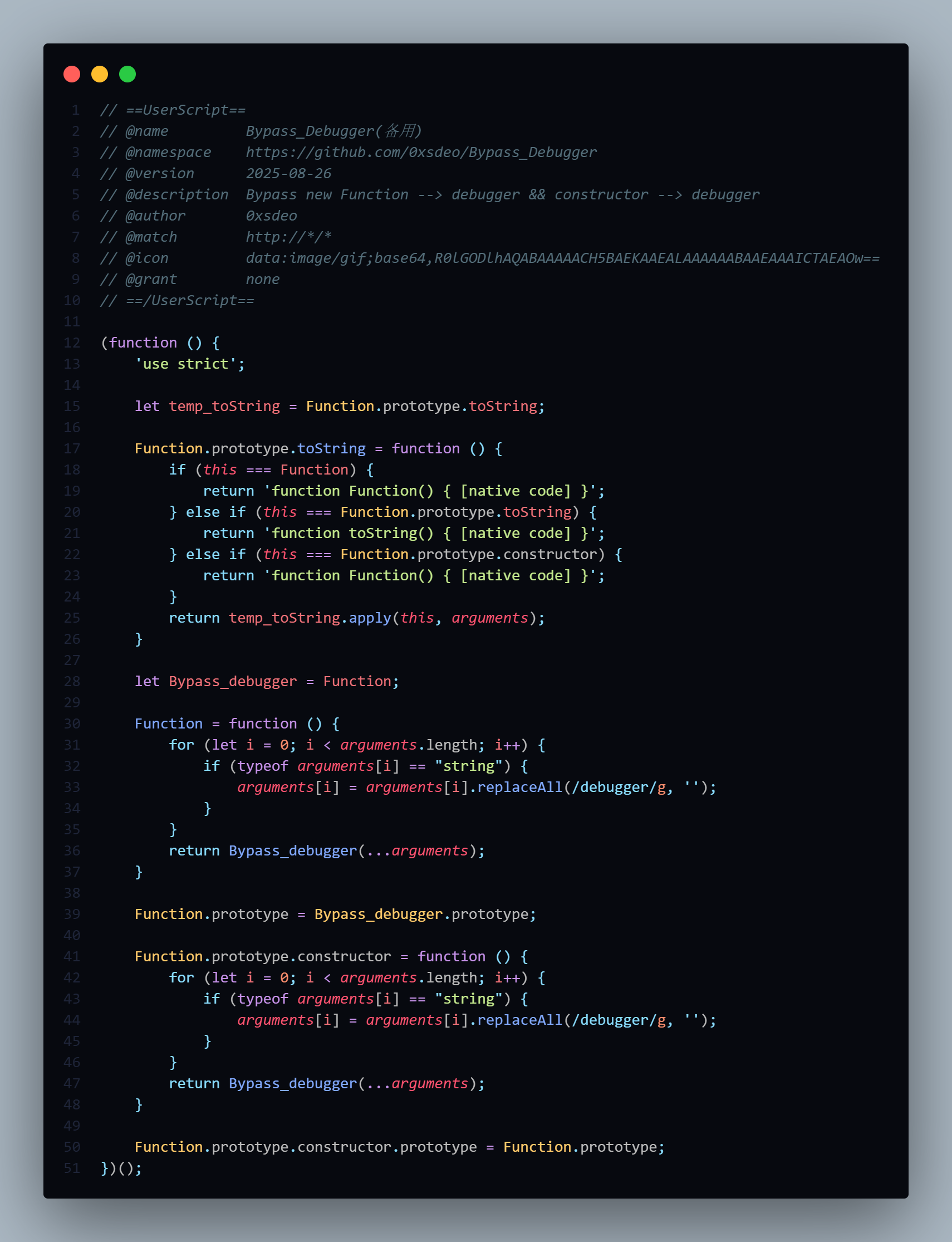
这就是绕过全局前置守卫的核心点:我们配置的每个全局前置守卫(也就是一个函数)都会被push到一个数组里,当我们访问的路由能匹配到某个路由守卫的规则时,就会去执行它。所以我们绕过全局前置守卫的核心点就是不要将这些函数push到这个数组里即可,hook脚本我已经写好了:

该脚本可以有效绕过全局前置守卫,实现原理很简单,由于vue配置全局前置守卫都是将每个函数push到一个数组里,那么我只要hook掉push方法即可,然后在方法中拿到堆栈信息,只要堆栈信息中有beforeEach我们就能确定这个push动作是加载全局前置守卫规则的。以及为了不影响其他push动作,我做了判断堆栈信息中是否有beforeEach字符串以及判断堆栈信息是否有4行,如果不足4行就代表这个push调用和beforeEach没关系,最终实现全局前置守卫的绕过。
实际上绕过全局前置守卫还是比较简单的,但是我们也能从官方文档中知道,vue router提供了多种路由守卫,我汇总了一下有哪些守卫可以实现取消导航:
全局前置守卫(beforeEach)
全局解析守卫(beforeResolve)
路由独享的守卫(beforeEnter)
组件内的守卫(beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave)全局前置守卫我们已经解决了,现在让我们看看全局解析守卫,以下是一个示例:



可以看到其实全局解析守卫(beforeResolve)实际上也是将函数push到数组里的,所以我们依然能用老办法实现绕过全局解析守卫:

让我们来看看效果:

成功绕过,现在让我们访问content试试能不能成功:

成功访问,说明我们此时已经绕过了全局解析守卫。
接着让我们来看一下路由独享的守卫,以下是一个示例:

可以看到,配置路由独享的守卫和其他两个守卫并不一样,其他两个守卫是全局守卫,各自要调用beforeEach和beforeResolve方法,而它是某个路由独享的守卫,所以直接把守卫写在相对应的路由规则中即可,我们来看一下效果:

访问/content:

可以看到被禁止访问了,说明守卫起作用了,面对这种守卫其实也很好绕过,直接替换即可,因为它不用调用push方法所以我们也没办法去hook绕过,只能去替换:

删除保存:

现在刷新访问/content路由试一下:

成功访问,说明我们已经绕过了路由独享的守卫。
最后一个组件内的守卫我目前不打算继续绕过了,因为一般最常用的就是全局前置守卫,我给大家看一下deepseek对组件内的守卫的描述:

我们可以通过这些使用场景得知,这些路由守卫实际上都涉及到一些敏感操作,我目前比较担心绕过后发生一些不可避免的错误,所以暂时不会去进行绕过,我觉得绕过上面这三个路由守卫足以应付我们平时在渗透中遇到的vue站点。
脚本我已经上传到了github上,地址:https://github.com/0xsdeo/Hook_JS/blob/main/vue/Clear_vue_Navigation_Guards.js。
最后我想说一下:我这个脚本实际上也可以用在判断目标站点是否是vue框架,如果控制台输出了清除路由守卫的信息,那么就代表目标站点使用了vue router,也就证明了目标站点是vue框架,不过这种方式也比较鸡肋,如果没有输出也不能说明目标站点不是vue框架,这个功能可以作为判断目标站点是否是vue框架的一个辅助标准。
0x06 总结
本文内容较多,我将上文的重点总结到这里,方便各位梳理。
判断目标站点是否是vue框架
1.页面中有id为app的div。2.站点只有一个index.html3.查看路由是否表现为#打头。4.遍历DOM元素去判断目标站点是否是vue框架,可使用VueCrack插件的hook脚本中的findVueRoot函数。5.也可以用我的hook脚本进行判断,如果控制台输出了清除路由守卫的信息,那么就代表目标站点使用了vue router,也就证明了目标站点是vue框架,不过还是最好使用第四种方式去判断。
最大化收集vue框架下的js
vue框架其实可以构建多种类型的应用,比如本文主要针对的单页应用(SPA),其他类型的应用也可以写,比如MPA(多页应用)、SSG (静态站点生成)、SSR (服务端渲染),但在本文我们主要还是谈要使用vue router的应用类型,而单页应用(SPA)就必须要使用到vue router,也就是本文所针对的应用类型。
由于单页应用只有一个index.html,所以每个路由要引用的js文件名都会写在js中,在本文中我提到过三种js引用方式:
1.每个路由所需的js文件名被完整写在路由规则中。2.传统的Webpack打包,需要自行拼接获取完整js文件名。3.prefetch预加载js。
前两种方式需要我们手动去代码中寻找js文件名,第二种甚至需要我们手动拼接,比较繁琐,获取他们的最简易方式就是进入目标站点的所有路由,此时就会加载各个路由所需的js,就不用我们手动去拼接或者去代码中找了。
第三种方式比较简单,此类网站会预加载所有路由所需的js,就不需要我们去代码中寻找了。获取此类网站的js需要开着F12并开启停用缓存,否则浏览器会从缓存中加载js,这样在burp中是没有流量的。不过有一点需要注意,这种预加载的js在F12中是看不到响应内容的,不过实际上是不会影响到findsomething(熊猫头)插件正则匹配的,依旧能正常实现匹配到这些预加载的js。
绕过路由守卫
对我们有影响的路由守卫:
全局前置守卫(beforeEach)
全局解析守卫(beforeResolve)
路由独享的守卫(beforeEnter)
组件内的守卫(beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave)前两个使用我的hook脚本即可绕过:https://github.com/0xsdeo/Hook_JS/blob/main/vue/Clear_vue_Navigation_Guards.js,第三个需要自行替换,最后一个组件内的守卫我暂时不会针对性的去写hook脚本,这几个路由守卫可能会涉及到一些敏感操作,我比较担心绕过之后会发生一些不可避免的错误,所以暂时不会去进行绕过。








 会员专属
会员专属


请登录后查看评论内容