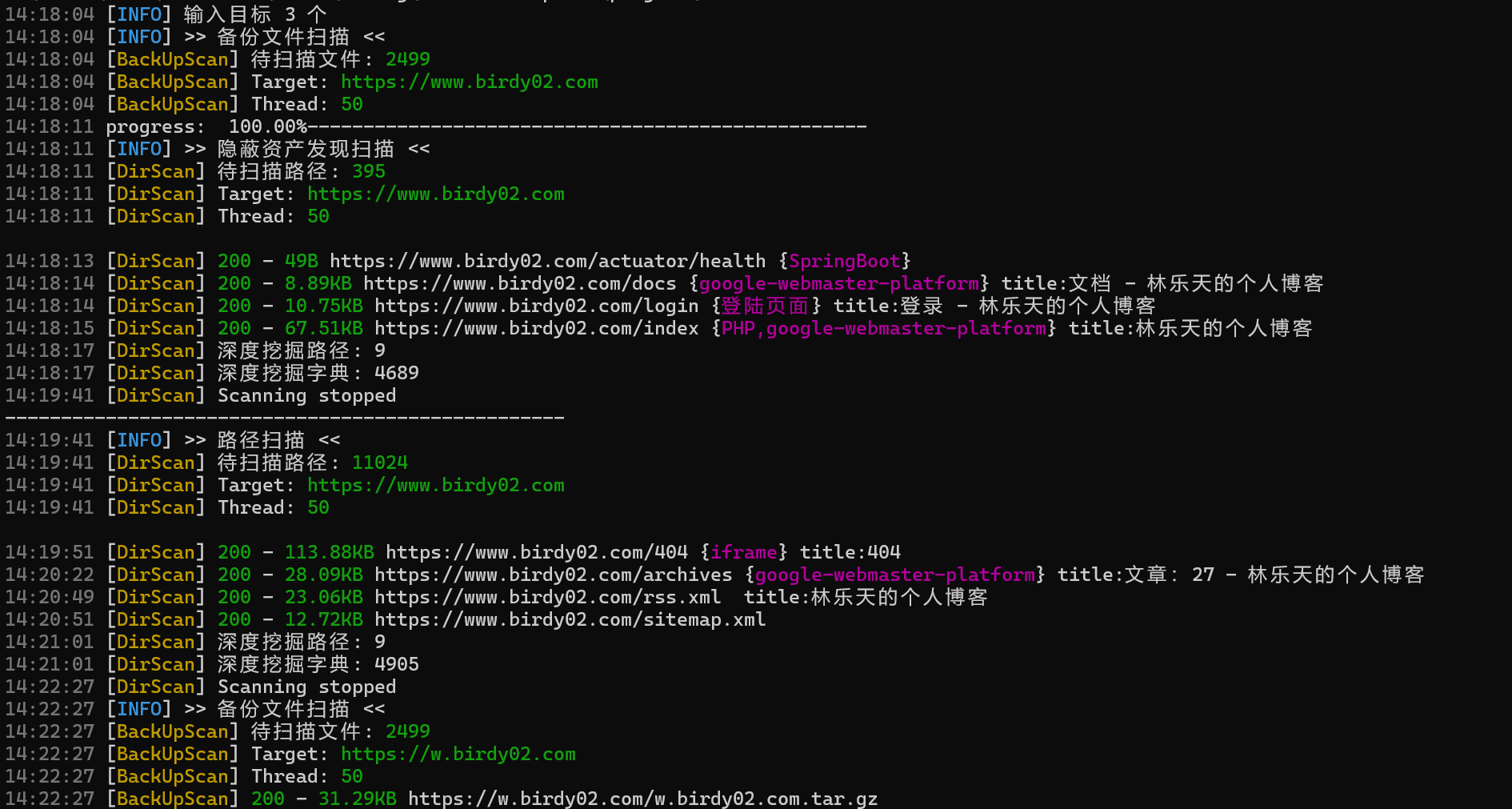
DirScan —— 高性能 Web 目录与隐蔽资产扫描工具


- 作者:林乐天
- 版本:v1.5
- 更新:2025-10-08
- 博客:https://www.birdy02.com
- PS:工具目前处于测试阶段,已经确保了功能使用正常。
DirScan 是一款高效 Web 目录、备份文件、隐蔽资产发现与web资产存活快速验证工具。工具设计轻量、并发友好,支持代理、认证与自定义请求头,内置指纹识别库,结果可导出excel,便于后续分析与报告生成。
主要目标是快速发现隐蔽资产、备份文件、目录与可能被遗留的常见敏感文件,从而为安全评估、红队演练和资产盘点提供高质量的初步数据。
DirScan 所使用的都是作者独立设计的模块,如:备份文件检测、请求方法库、路径扫描模块,并且每个模块都在持续优化更新,这些支持库共同支撑起了DirScan的实现。
特点
- 备份文件: 基于输入目标自动生成扫描字典,与内置字典的结合扫描
- 隐蔽资产: 内置数百个
产品、框架的目录字典 - 资产存活: 对输入的URL(列表)快速进行存活探测,通过输出状态码、指纹等信息快速筛选目标
- 严格校验: 对不同文件有不同的判断规则,而不仅是判断响应状态码
- 深度挖掘: 基于爬取到的路径与内置路径拼接
产品、框架字典,深度挖掘隐藏在目录下的资产信息 - 连接复用: 第一次建立
TCP连接后,重复使用该连接发送Http请求,速度与性能提升3~5倍
主要特性
- 高并发扫描,支持自定义线程数以提升扫描速度。
- 多种扫描模式:
allbackupdircmsinfo自定义扫描字典,按需选择减少误报与加速任务。 - 支持 HTTP 代理(含带认证的代理)。
- 支持 Basic Auth、Cookie 与自定义请求头文件。
- 默认识别 Web 指纹发现潜在高危资产。
- 扫描结果可导出为 Excel,字段包含路径、标题、状态码、响应大小与指纹结果。
- 命令行工具,易集成到 CI / 自动化流程。
使用说明
-a, –auth string Basic认证信息 [username:password]
-c, –cookie string 请求Cookie [SESSION=xxxx;]
-d, –depth 跳过深度挖掘功能 ps:启用可挖掘隐藏在二级目录下的资产
–header string 请求头文件,不包含内容 -> [GET /index HTTP/x.x]
-h, –help help for dirScan
-m, –mode string 指定扫描的模式:
* all: 全模块扫描-调用所有扫描模块,扫描顺序[backup-cms-dir]
* backup: 备份文件扫描-基于输入目标生成和内置字典,对目标可能泄漏的数据库、web等备份文件进行检测.
* dir: 内置路径扫描-使用内置1w+路径对目标进行碰撞,能发现泄漏文件或路径.
* cms: 资产发现扫描-扫描隐藏在特定目录下的资产,如: /nacos
* info: 只对输入目标列表进行探测和基本信息识别,一般用于快速批量检测网站信息中.
* dist.txt: 路径字典扫描-输入自定义字典,使用dir模块进行碰撞,自定义字典不支持深度挖掘. (default “cms”)
-p, –proxy string 代理服务器地址 [http://127.0.0.1:8080 认证:http://username:password@127.0.0.1:8080]
-r, –retry int 请求失败后重试次数 (default 2)
-t, –thread int 并发线程数 (default 20)
–timeout int 请求超时时间[秒] (default 4)
-u, –url string 输入目标 [http(s)://xxx:xx 或 urls.txt,urls.csv(列:扫描目标,任务描述)]
–user-agent string 指定User-Agent头
常见用法示例
单个目标快速扫描:
dirscan -u https://example.com
从文件批量扫描(urls.txt 每行为一个 URL):
dirscan -u urls.txt -t 100 -m cms
批量扫描存活资产信息
dirscan -u urls.txt -t 100 -m info
通过代理扫描并设置超时和字典
dirscan -u https://example.com -p http://127.0.0.1:8080 --timeout 10 -w ./wordlists/common.txt
输出说明
工具会把扫描结果导出为 Excel 文件,常见字段如下:
file — 发现的文件
- 目标描述:任务描述、一般可用于指定归属单位
- 发现时间:文件、路径的发现时间
- 文件名:扫描的文件名称
- 文件大小:响应体大小(字节)
- 请求Url:文件的URL地址
- 响应状态:HTTP 响应码
- 请求头:Http的请求头
- 响应头:Http的响应头
- Hash:响应体的hash值(如果被Head方法扫描到,则无hash值)
dir — 发现的目录
- 目标描述:任务描述、一般可用于指定归属单位
- 发现时间:文件、路径的发现时间
- 目标URL:文件的URL地址
- 请求路径:请求的URL路径部分
- 请求协议:请求的协议
- 主机名:请求的Hostname
- IP地址:请求解析的IP地址
- 响应标题:响应网页的标题
- 响应状态:HTTP 响应码
- 响应长度:响应体大小(字节)
- 指纹:检测到的指纹信息
- 请求头:Http的请求头
- 响应头:Http的响应头
- Hash:响应体的hash值
常见问题(FAQ)
问:如何减少误报?
答:我们通过对响应数据进行清洗和对比,可以排除掉大部分的无效数据,并且内置一批特征判断的路径,极大降低了误报率。
问:是否支持登录态扫描(如表单登录)?
答:当前版本支持 Basic Auth、Cookie注入与自定义请求头,只需要将认证后的 token(验证) 信息添加到请求中即可。
最近更新
2025-10-04 (v1.4)
1. 增加目标可用性检测
2. 新增预检测 `Head` 与 `Get` 支持方法,响应状态不一致时禁用Head检测
3. 扫描模式默认更改为 `cms`
4. Get扫描增加请求头 `Range: -499`,避免响应文件过大导致超时
5. 更新指纹库,增加规则
6. 取消Http请求的强制HTTP2
7. 修复深度挖掘功能判断错误的代码块
8. 修复字典列表去重缺陷 PS: 导致缺少300+路径
9. 增加info扫描模式,主要用来批量扫描URL信息,返回内容与dir一致
2025-10-08 (v1.5)
1. 增加扫描结果推送功能,扫描完毕后可通过机器人推送通知到钉钉或飞书
2. 修改 `-d` `–depth` 参数功能由启用改为跳过
3. 扫描结果中增加扫描路径、任务描述列(excel中体现),备份文件扫描仅增加任务描述列
4. 输入目标支持任务描述(baidu.com,百度),同时兼容仅输入目标列表
5. 增加扫描失败重试次数、修复以并发数作为重试次数bug
Bug
- 感谢用户 长安城第一美 反馈的路径缺失问题。原因:字典列表去重缺陷导致.
其他
如何获取:底部附件下载
了解更多:https://www.birdy02.com/docs/dirscan





请登录后查看回复内容